Towards Natural Natural Language Processing
Term Paper for
263-5353-00L Philosophy
of Language and Computation
Structuralism: The Search for the
Right Units
In natural language processing, the chief subject of research is language in its textual form. The grounding of text in speech, the primordial form of language, is taken for granted. Recently, language understanding, production, and discourse on an acoustic level has been approaching practical feasibility through large-scale statistical modeling with neural networks. In this essay, we set out to explore the connection between spoken and written language from a structuralist viewpoint and examine works from both (textual) language and speech processing. Finally, we present recent work on spoken language processing along with opportunities and challenges for future work.
People attach even more importance to the written image of a vocal sign than to the sign itself. A similar mistake would be in thinking that more can be learned about someone by looking at his photograph than by viewing him directly.
Introduction
The central tenet of structuralism is that complex phenomena, such as human language, can only be understood by studying the relations of their individual elements. This approach necessitates a suitable definition what constitutes an element. Fundamentally, language manifests as acoustic waves subject to biological but also information-theoretic constraints, such as discreteness and duality of patterning (Hockett 1960). These constraints are reflected in the symbolic abstractions, i.e., writing systems, that emerged to represent language (Meletis 2020). From the outset, structuralist linguistic theories were designed to encompass all manifestations of language, starting at the acoustic level, albeit with the assumption of an underlying symbolic representation. However, Harris remarks that a specific choice of elements to study affects the analyses and insights that can be obtained:
Phonology and morphology, therefore, each independently provides information concerning regularities in selected aspects of human behavior. The general methods of scientific technique are the same for both: associating discrete elements with particular features of portions of continuous events, and then stating the interrelations among these elements. But the results in each — the number of elements and classes of elements, the type of interrelations — are different. [...] phonology is more useful in taking down anthropological texts, learning a new dialect, etc., while morphology is more useful in the understanding of texts, in discovering “what is said” in a new language, etc. (Zellig S. Harris 1963, 22–23)
Echoes of Harris' argument are clearly audible when considering how fields of research concerned with syntactic and semantic understanding selected text as their medium of choice, whereas phonetics is of interest, for example, in acoustic modeling for automatic speech recognition (ASR). One may however question such distinctions based on the medium of language; as Saussure stresses in the Course on General Linguistics, “The linguistic object is not both the written and the spoken forms of words; the spoken forms alone constitute the object.” (Saussure 1916, 23–24). Can the strong focus on textual representations in contemporary NLP thus be considered harmful, and which opportunities are potentially missed?
To set the stage, we will briefly review how Saussure and Harris relate the spoken and written form of language in their works, and then trace how the issue of defining the proper elements of study, linking back Harris' observation above, developed similarly in text and audio applications in the wake of deep learning. We then discuss spoken language modeling and conclude with challenges and opportunities in this emerging field.
Spoken and Written Language in Structural Linguistics
Structuralism was initially developed by Ferdinand de Saussure and
treated in a series of lecture notes in the posthumously published
Course of Linguistics. At its core, Saussure establishes the linguistic
sign as the chief unit of interest, which in turn consists of
the signified (the mental concept) and the signifier
(the physical realization). Notably, the signifier is defined as a
“sound-image” of a concept and hence concerns the acoustic level.
Indeed, Saussure objects to studying language purely in its written
form, going so far as to speak of a “tyranny of writing” that not only
“disguises” but “influences and modifies language”, and criticizing
earlier linguistics for confusing language and writing (Saussure 1916,
31;24) The insistence on spoken language might stem in part
from Saussure's interest in how languages evolve over time (“to describe
and the trace the history of all observable languages” is listed as the
first item of the scope of linguistics), and his observations on how
grammar and writing can stifle such evolution and in turn obscure
developments that actually took place. However, he also emphasizes the
need to study written language, in order to be “acquainted with its
usefulness, shortcomings, and dangers.”
.
The structuralist approach is then further developed by considering the fundamental element (the sign) in detail and positing that it is defined solely by separating it from other signs, at which point its function can be studied by the relation to other signs. This approach does however lead to immediate difficulties, as Saussure well admits: it is not at all clear how such a separation should work in practice, and Saussure is dissatisfied with resorting to concepts of syllables, words or sentences (Saussure 1916, 105).
In Structural Linguistics, Zellig Harris sets out to develop
practical methods for studying interrelations of linguistic elements. As
an American structuralist, Harris was concerned with synchronic
linguistics, investigating a single language over a brief period of
time, presented as a corpus of utterances. The linguistic element is now
defined on a symbolic level, which is integral as “[these] elements can
be manipulated in ways in which records or descriptions of speech can
not be: and as a result regularities of speech are discovered which
would be far more difficult to find without the translation into
linguistic symbols.” (Zellig S. Harris 1963, 18). While
Saussure posits that “linguistic signs, though basically psychological,
are not abstractions,” (Saussure 1916, 15) Harris admits that he
does in fact perform an abstraction of speech and that, consequently,
many features of speech cannot be capturedFor Saussure, language and speech are to be clearly
separated, leading to the conclusion that “we can dispense with the
other elements of speech; indeed, the science of language is possible
only if the other elements are excluded,” (Saussure 1916, 15). On the other hand,
Harris writes that “if we ever become able to state with some regularity
the distribution of these other behavioral features, we would associate
them too with particular linguistic elements.” (Zellig S. Harris 1963, 19).
. The notion of working with utterance fragments
themselves is dismissed as defining corresponding elements would be too
cumbersome, and because once a subdivision of speech yields
correspondences of symbols between utterances, nothing would be gained
by further dividing elements into their constituents. With respect to
current deep learning methods applied to text and audio signals,
however, this reasoning does not hold up well as we shall see in the
next section.
Harris distinguishes between phonetic and morphological analysis.
While phonemes and morphemes are portrayed as two sides of the same coin
in that both can fully describe an utterance, they differ in their
purpose. As alluded to in the introduction of this essay, Harris regards
morphemes as suitable to determine the meaning of an utterance.
Consequently, while Harris spends considerable effort on distributional
analysis on a phonetic level, his work culminates in approaches to
derive morphological structurePhonetics was of high importance to American
structuralism, not at least due to an interest in the study of
indigenous languages of the Americas which frequently lacked
standardized writing systems. Harris also performed distributional
analysis on the Cherokee language (Zellig S.
Harris 1954), for which a written form was however
available.
. Similar attitudes can be found in other structuralist
works from this period, such as Firth's “no meaning without morphology”
(Firth
1957). With Chomsky shifting focus to analysis of whole
sentences, units of interested moved to yet more abstract levels as it
was regarded as “absurd, or even futile, to state principles of sentence
construction in terms of phonemes or morphemes” due to the complexity
that such descriptions would entail (Noam Chomsky 1957, 59). This is not to
say that the relevance of phonetics in linguistics disappeared; Chomsky
himself set out to define grammars for production at a phonetic level
several years later (N. Chomsky and Halle 1968).
Statistical Modeling of Audio and Text
Pioneering work in artificial intelligence, in particular in natural language processing (NLP), was carried out under a strong structural influence from Chomsky and Wittgenstein (Biggs 1987). Liddy (2001) notes that Chomsky's work resulted in a split of the NLP community, with generative grammar playing an important role in language processing, while statistical methods dominated applications of speech processing. With renewed interest in connectionist methods in the last decade due to the success of deep learning, statistics is at the heart of today's NLP. In this section, we will give examples how deep neural network models encourage the usage of primitive units that carry no semantic information themselves: individual characters.
Text
When working with text, a natural choice for an elementary unit seems
to be the word. The definition of a word is however not as trivial as it
might appear. Mielke
et al. (2021) review past and recent trends in
tokenization (transforming text into primitive units) for NLP
applications and provide several examples where difficulties arise,
e.g., when deciding on a tokenization for “don't”. Besides technical
feasibility, two main considerations determine the choice of units in a
statistical setting: (1) the ability to gather useful statistics from a
given training corpus, and (2) how well these statistics can be
generalized to new dataGeneralization is determined a combination of many
factors, but deciding which data to model in the first place is an
important one. Which data a system should generalize to further depends
on the particular research setting considered.
. With the first point being addressed by ever-growing
datasets, the second point becomes more relevant with the increasing
capabilities and applications of NLP models. For example, a machine
learning system might encounter unseen words at test time; a graceful
fall-back might consider the new word's morphological information, for
example. With powerful neural network models that can model long
sequences, it is appealing to consider characters as the fundamental
element (Sutskever,
Martens, and Hinton 2011; Al-Rfou et al. 2019). But even here
things are not as clear-cut: when opting for raw bytes or for a
particular encoding such as Unicode, different trade-offs arise (Mielke et al.
2021). The prevalent approach in today's systems is sub-word
modeling, e.g., by combining individual letters based on their
co-occurrence (Sennrich, Haddow,
and Birch 2016). This compromise between words and characters
allows for generalization while processing of several thousands words in
sequence is still feasibleSuch trade-offs depend on the balance between available
hardware (to ensure reasonable training times) and limitations in
modeling and are thus subject to constant and rapid change.
. Interestingly, recent work attempts to sidestep the
issue of selecting textual units by considering visual language
processing, e.g., by modeling images with rendered sentences (Salesky, Etter, and
Post 2021) It is tempting to imagine how Saussure would have
reacted to such a setup.
.
Audio
In traditional speech transcription systems, separate models are
utilized for audio and text modalities and combined with Bayes' rule to
find the most likely text sequence \(T^*\) given an audio signal \(X\), i.e., \(T^*
= \operatorname{argmax}_T p(T | X) = \operatorname{argmax}_T p(X | T)
p(T)\). The first quantity, \(p(X |
T)\), is referred to as the acoustic model and serves as a good
example regarding the fundamental units used in audio processing. The
acoustic signal \(X\) is typically
represented as features over fixed-length audio fragments, extracted via
Fourier transforms. Which units should be predicted from such
featuresFor ease of exposition, we disregard the problem of
finding the optimal sequence of linguistic units and focus
solely on the classical acoustic modeling task, i.e., predicting a
single unit wrt. given acoustic features. In full ASR systems, a decoder
integrates both acoustic and language model scores to determine a
transcription hypothesis.
?
Historically, directly predicting letters or sub-word units from
audio in continuous speech recognitionIn continuous speech recognition systems, words and
sentences (and possibly speakers) are not explicitly separated by
pauses.
was considered practical only for languages with a strong
correspondence between written and spoken forms, such as German or
Spanish (Killer, Stuker, and
Schultz 2003). For languages such as English, phonetic units
were of higher interest, which came with the additional requirement of
dictionaries to map words to their corresponding phone sequences. Early
systems used simple phonetic units from a manually designed set of
phones, but significant advances were made by a division into
subphonetic states and taking context information of surrounding states
into account (Schwartz
et al. 1985). Eventually, advances in neural network modeling
and larger training corpora enabled the prediction of characters
directly from digital wave form representations, alleviating the need of
expert knowledge on pronunciation and audio featurization (Collobert,
Puhrsch, and Synnaeve 2016).
Representation Learning
The conclusion thus far seems to be that for language tasks, modeling techniques are ultimately converging single letters as the unit of choice. While letters do not constitute any meaning in a linguistic sense (i.e., the smallest units of text that convey meaning would be morphemes), this is in line with the promise of deep learning to construct suitable internal representations from raw signals automatically (LeCun, Bengio, and Hinton 2015). However, a key assumption in NLP is that the tasks of interest are already defined in a textual form: parsers are evaluated on parsing text, language models on generating text, and speech recognition systems on transcribing speech to text.
A separate branch of contemporary deep learning literature deals with learning representations as a goal in itself. Such techniques have recently been of high interest under the term of self-supervised learning, i.e., representation learning from unlabeled data, and can be broadly filed into two categories. In generative representation learning, the aim is to learn a compressed representation that allows for the reconstruction of the input or a future datum (Ballard 1987; Kingma and Welling 2014); in contrastive learning, the learning signal is the disambiguation of similar from unrelated data (Arora et al. 2019). These approaches can also be combined; one example is Contrastive Predictive Coding (CPC) (Oord, Li, and Vinyals 2018) in which a representation is learned to model (representations of) future observations in sequential data, with a contrastive loss to avoid explicit prediction of these observations.
Could the issue of unit selection thus be sidestepped by learning a representation instead? In any case, it is necessary to define the input data, which constitutes a definition of the unit's “natural” instantiation, e.g., tokenized text or a fixed-length temporal signal. On the other hand, representation learning enables a direct application of structuralist maximes from first principles: the construction of elements (here: representations) defined by their similarity to other elements. Harris' methods for identifying phonetic units relies primarily on the ability to substitute fragments of utterances with each other (Zellig S. Harris 1954, 29) — in other words, elements are further defined by the context in which they occur, which is implemented in methods such as word2vec (Mikolov et al. 2013).
Spoken Language Processing
A recently emerging work stream considers natural language processing without textual representations (Lakhotia et al. 2021; Kharitonov et al. 2022). This can be regarded as a return to the origins of Saussure's work, but there are several further research opportunities by focusing on spoken language. First, putting fundamental differences across modalities aside, breaking the reliance on text can be regarded as a next step in terms of data presentation, advancing to units more fine-grained than individual characters. Second, a key question in linguistics is how humans acquire language. Chomsky postulates that humans are endowed with innate abilities for language learning and rejects the notion of language learning purely from external feedback (Noam Chomsky 1975, 1959). However, concrete evidence for either hypothesis has remained elusive to date. With large neural network models approaching human capabilities in text understanding and generation, insights into language acquisition might be derived from their study (Warstadt and Bowman 2022). In this line of thinking, it can be argued that one may need to expose learned models to identical modalities, i.e., speech rather than text (Dupoux 2018). Finally, a practical benefit is the option to deploy systems to languages without a writing system, which constitute the majority of the world's languages (Tjandra, Sakti, and Nakamura 2019).
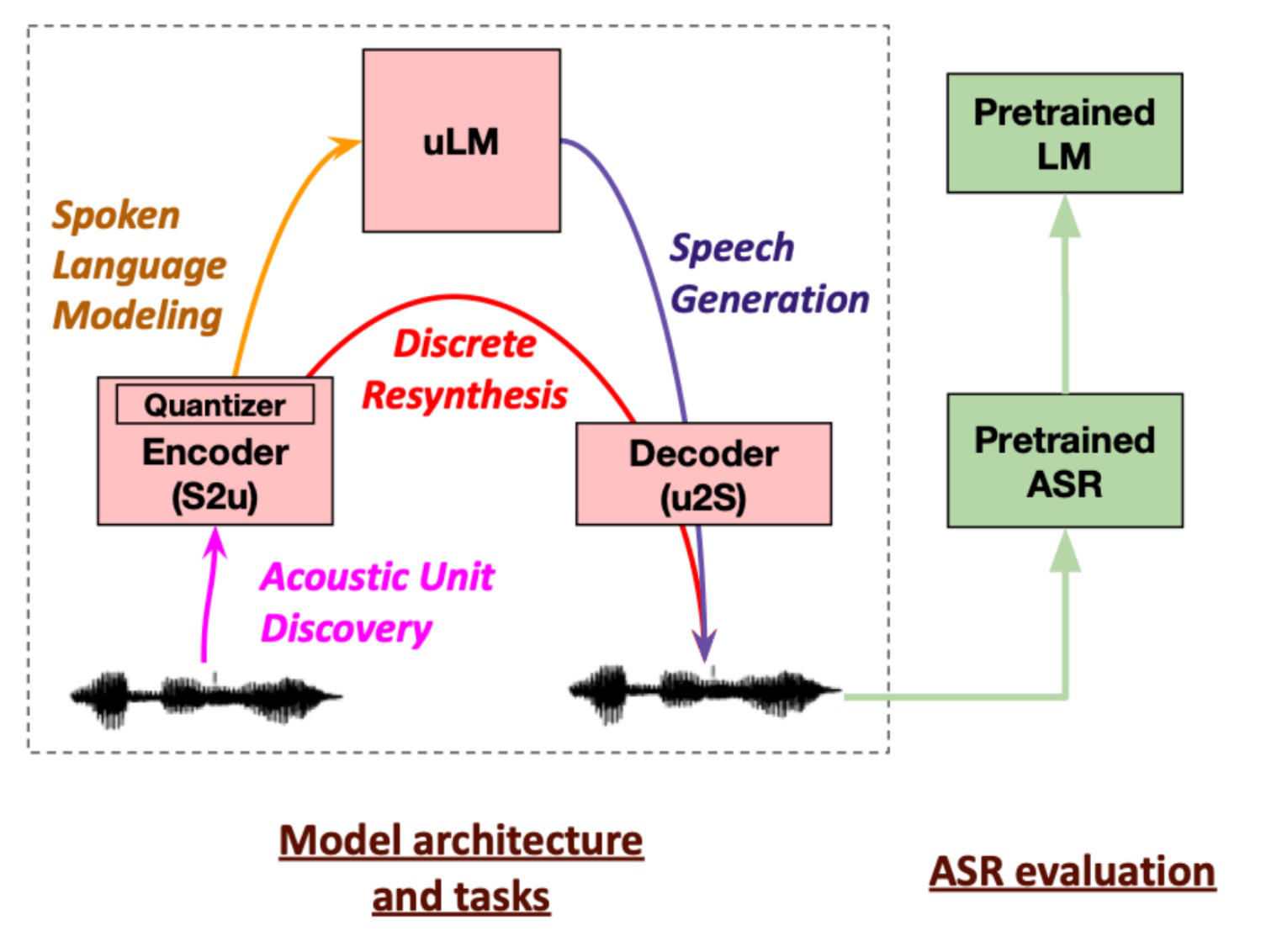
As an exemplary system for spoken language generation, we consider the setup proposed by Lakhotia et al. (2021) and depicted in the figure above. In a first stage (S2u), acoustic units are discovered via representation learning. Here, techniques such as CPC are used to obtain representation for fixed-length audio segments (here: 10ms), and discrete units are then obtained by clustering the representations via k-means. A language model (uLM) is then trained on sequences of discrete units as they appear in the dataset, implemented as a Transformer (Vaswani et al. 2017). Finally, a decoder (u2S) is employed to translate acoustic units into spectrogram features for subsequent audio synthesis (Shen et al. 2018). The resulting system can prompted with an audio segment and predicts possible continuations, akin to large language models like GPT (Brown et al. 2020).
In the setting above, the explicit discovery of acoustic units seems
to be add odds with the trend towards building end-to-end deep learning
systems. The motivations for discrete acoustic units are two-fold.
First, discrete units allow the sampling of sequences from the language
model based on class probabilities obtained via softmax normalization,
whereas sampling directly on the level of acoustic features would
require the assumption of an underlying probability distribution.
Predicting a sequence of raw wave form samples would again involve
discrete units, but leads to enormous sequence lengths; furthermore,
variations at this level have only little influence on the resulting
sound so that, e.g., generating two different spoken words would involve
a large number of suitable correlated sampling stepsBoth issues — handling very large sequences as well as
learning flexible distributions and sampling from them — are important
topics in current generative modeling research, so future work may well
challenge the motivation outlined here.
.
In follow-up work, it was pointed out that acoustic unit discovery via representation learning fails to capture non-phonetic information and thus misses out on one potential of spoken language processing: the integration of non-verbal and prosodic features which convey, e.g., emotion and emphasis (Kharitonov et al. 2022). As a possible solution, the duration (number of repetitions) of clustered acoustic units as well as the fundamental frequency can be modeled explicitly with the uLM component.
A major challenge addressed in Lakhotia et al. (2021) is the evaluation of spoken language generation models; as noted above, typical NLP benchmarks are defined on a textual level. While native speakers can judge the generated speech in terms of intelligibility and semantics, automatic evaluations are valuable for swift and deterministic benchmarking. Their work proposes evaluation methods for both intermediate models and overall generation. Acoustic units are evaluated by estimating whether units that fall into the same discrete category are closer to each other than units in separate categories (Schatz et al. 2013) — a notion which again corresponds to Harris' criteria. Language-level performance is measured by a word spotting task, in which single-word utterances of real and pseudo-words (e.g., “brick” vs. “blick”) are discriminated based on uLM scores (Nguyen et al. 2020). Finally, generated speech is evaluated by utilizing an off-the-shelf speech transcription system. Intelligibility can be gauged with transcription system's acoustic model: an utterance is encoded and decoded with the S2u and u2S components, and the discrepancy between acoustic model output of the original and re-synthesized utterance is computed. Judging the content of the generated text is however more involved, and the authors propose to measure two signals. First, the diversity of words within a transcribed sentence is measured on the level of words and word combinations. Second, the perplexity of a standard language model is computed, serving as a (weak) proxy on whether the entire transcription in sensible (as in, likely with respect to a given corpus of text).
Outlook
What role with spoken language processing play going forward? While practical benefits exist, e.g., the inclusion of languages that are spoken only, or integration of non-phonetic features into language processing and analysis, today's primary medium for human-computer interaction is text. Furthermore, text is increasingly hailed as the interface of choice for content generation in such diverse modalities as images, animation, or code (Ramesh et al. 2022; Zhang et al. 2022; Chen et al. 2021). On the other hand, one can imagine shifts in user interfaces, e.g., fueled by creation and consumption of richer content such as video, or an expansion of speech interfaces, e.g., in immersive environments in which interaction via speech is natural, to pave the ground for new applications. For example, a conversational agent could directly react to irony in a user's voice, and likewise provide emotional cues in its response (if so desired). Dupoux (2018) argues that modeling spoken language can provide insight into language acquisition in children, tackling the problem from a reverse-engineering point of view. This may allow researchers to address the bootstrapping problem, for example, where children apparently learn multiple interdependent aspects of language concurrently (e.g., learning phonemes requires the concept of words while learning a vocabulary requires knowledge of phonemes). Constructing artificial systems that successfully acquire language purely from acoustic signals could thus put Chomsky's universal grammar hypothesis to the test. Likewise, the search for the most suitable units of language may be advanced, either with improvements in representation learning for explicit discovery, or from studying intermediate representations in end-to-end models.
What are open challenges in this field? As mentioned above, current limitations in deep learning necessitate a separate learning stage to acquire acoustic units. The question of how these units are acquired has not been settled, as we've discussed in the context of capturing non-phonetic information. Besides finding good inductive biases for representation learning, there are further design considerations, such as specifying the number of discrete units, or whether discretization is necessary at all. Nguyen, Sagot, and Dupoux (2022) perform a preliminary investigation into the latter issues, albeit without considering the generation of speech, and arrive at the conclusion that continuous acoustic representations generally perform worse and that the number of units should at least amount to a typical phoneme inventory of about 40 units. Finally, relying on speech transcription systems for evaluation is at odds with the promise of being able to model low-resource languages, or those without a writing system. By applying this line of research to languages that have been extensively studied in NLP and ASR, the additional requirement for techniques to generalize across languages might alleviate this issue (Lakhotia et al. 2021).
Finally, has the circle to Saussure been closed for good now? Indeed, spoken language processing picks up the proposition to leave textual representations aside and is likewise motivated by a desire to access the “true” manifestation of language. The results obtained in recent work are at least starting to undermine Harris's claim that, ultimately, textual representations are more useful for understanding “what is said”. Scholars have however also lamented the downstream effects of early structuralism's focus on speech, and argue that the study of writing systems is useful on its own (Meletis 2020). For example, regarding possible new advances in understanding language acquisition, how would such findings apply to deaf people acquiring reading and writing facilities? A likely outcome is that spoken language processing adds to the overall canon of methodologies that can help us understand human language as a phenomenon, alongside the study of text. This would, once again, be in accord with Saussure's recognition of how both speech and writing systems mutually influence each other.